
Rodolfo M. Raya (rmraya@maxprograms.com)
Chief Technical Officer, Maxprograms
First published by IBM developerWorks, Feb 2005
Rodolfo M. Raya (rmraya@maxprograms.com)
Chief Technical Officer, Maxprograms
First published by IBM developerWorks, Feb 2005
Translation memories are essential pieces of a translation process. This third article in the "XML in localization" series demystifies TM technology and explains how Translation Memory eXchange (TMX), an XML standard, helps you to achieve independence from translation tool vendors.
Translation memory (TM) is a language technology that enables the translation of segments (sentences, paragraphs, or phrases) of documents by searching for similar segments in a database and suggesting matches that are found in the database.
TM is a fundamental part of modern computer aided translation (CAT) tools. It has become so common in the translation industry that the term "translation memory tool" is often used in place of "computer aided translation tool." However, these terms should not be used interchangeably, as CAT technologies also include machine translation, a computer technology based on linguistic rules and the use of bilingual dictionaries.
A TM system remembers translations that have been typed by a human translator. When the translator needs to work on a similar text, the system offers the previously saved version. This can save a lot of time when a translator works with repetitive texts, such as technical manuals, and can also help to achieve terminological consistency.
TM systems are basically search engines that specialize in performing two kinds of searches:
The level of similarity in fuzzy searches is called match quality. Its definition varies with each TM system implementation.
Similarity is often measured using Levenshtein distance, which refers to the algorithm written by Russian scientist Vladimir Levenshtein in 1965. With Levenshtein distance, you can count the number of insertions, deletions, and substitutions required to turn one phrase into another. For example, to change the word "magazine" into "magazines" you type one character ("s") and the difference between them is "1". One character in eight represents 12.5% (difference is usually measured against the source phrase), so a CAT tool using this method would indicate that the similarity between the two words is 87.5%.
The Levenshtein algorithm is very practical, but not practical enough. For example, a human translator can tell that the following two sentences are similar in meaning:
However, a program computing the number of keystrokes required to change one phrase into the other would say that those sentences are quite different, and may not offer translations from the database. Rearranging the words requires too many keystrokes.
With languages like English or French, it is easy to separate the words that compose a sentence, making it possible to take word order into account when measuring similarity. However, languages like Chinese or Japanese have no spaces between words, making it difficult to go beyond Levenshtein distance.
The key to providing better matches lies in the ability of the TM engine to break every segment into very small pieces and store them as a large collection of fragments in a database. The drawback to this is that the data storage requires that you spend a lot of time and effort doing proper indexing. Nevertheless, searching for fragments is faster than full text search combined with similarity calculations.
During the translation process, it is often necessary to transfer translation memories along with the documents being translated. Because the various participants in the process might have different TM systems, a standard for TM data exchange was created.
The Open Standards for Container/Content Allowing Re-use (OSCAR) group defined Translation Memory eXchange (TMX) (see Resources) as a common standard for allowing users to reuse text more effectively when working with different CAT tools or translation providers.
The formal definition of TMX shown at the Localisation Industry Standards Association (LISA) Web site states:
TMX (Translation Memory eXchange) is the vendor-neutral open XML standard for the exchange of Translation Memory (TM) data created by Computer Aided Translation (CAT) and localization tools. The purpose of TMX is to allow easier exchange of translation memory data between tools and/or translation vendors with little or no loss of critical data during the process.
Several complete translation tools are available to help you. Translators have a choice of tools that specialize in, among other things, general documentation, software localization, technical manuals, or brochures. When a translator needs to work with two or more tools, the ability to reuse translation memories across tools is a must. This is where TMX becomes the hero. Translation memories are valuable assets, and being tied to a proprietary database format is a bad idea. Open standards like TMX give translators, translation agencies, and companies that need localization a reasonable degree of independence from tool vendors.
A TMX document is an XML document whose root element is <tmx>. The
<tmx> element contains two children: <header> and
<body>.
General information about the TMX document is described in the attributes of the
<header> element. Additional information is provided in the
<note>, <ude>, and <prop> elements.
The main content of the TMX document is stored inside the <body> element. It
holds a collection of translations contained in translation unit elements
(<tu>). Each translation unit contains text in one or more languages in
translation unit variant elements (<tuv>).
The TMX DTD will allow a <tu> to contain a single <tuv> element, but this
does not make much sense. A segment is valuable when it helps to translate from one language
to another, thus the minimum number of languages in a <tu> element should be
two.
The text of a translation unit variant is enclosed in a <seg> element. All
formatting information inherited from the source document is kept inside inline elements.
All inline elements are described in Table 1.
| Element | Description |
|---|---|
| <bpt> | Begin paired tag: Used to delimit the beginning of a paired sequence of native codes. Each <bpt> element has a corresponding <ept> element within the segment. |
| <ept> | End paired tag: Used to delimit the end of a paired sequence of native codes. Each <ept> has a corresponding <bpt> element within the segment. |
| <hi> | Highlight: Delimits a section of text that has special meaning, such as a terminological unit, a proper name, or an item that should not be modified. It can be used for various processing tasks — for example, to indicate to a machine translation tool which proper names should not be translated; for terminology verification, it can mark suspect expressions after a grammar checking. |
| <it> | Isolated tag: Used to delimit a beginning/ending sequence of native codes that does not have its corresponding ending/beginning within the segment. |
| <ph> | Placeholder: Used to delimit a sequence of native standalone codes in the segment. |
| <sub> | Sub-flow: Used to delimit sub-flow text inside a sequence of native code — for example, the definition of a footnote or the text of a title in an HTML anchor element. |
| <ut> | Unknown tag: Used to delimit a sequence of native unknown codes in the segment. This element has been deprecated. |
Table 1. Inline elements
Inline tags depend on the format of the original document. In HTML, bold text is delimited
with opening and closing <b> tags, and those tags may be enclosed in
<bpt>/<ept> pairs when saved in TMX documents. In Rich
Text
Format (RTF), bold text starts with "\b" and it optionally may end with "\b0", so the
correct TMX inline tag to use is <ph>. Clever CAT tools can reuse
translations from different source formats despite differences in markup.
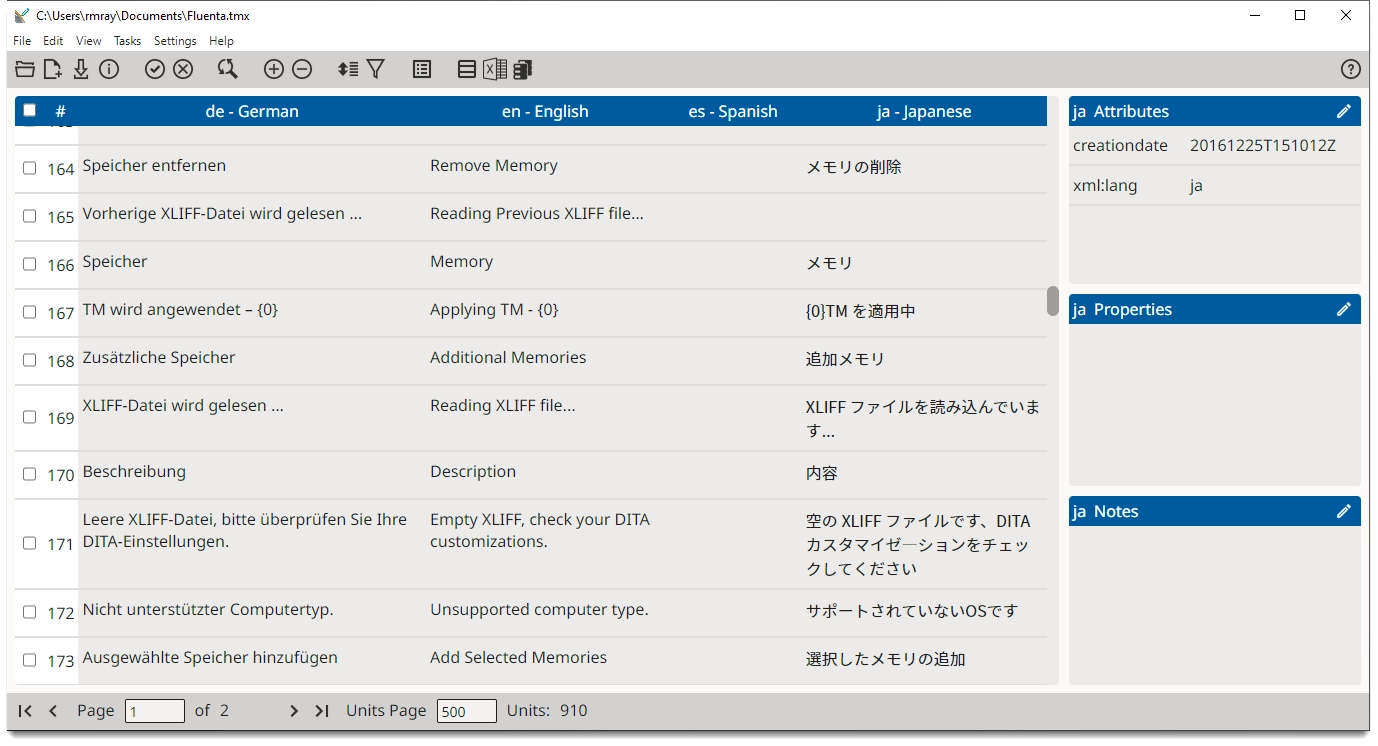
Figure 1 shows a fragment of sample TMX document with entries in English and Chinese. Figure 2 shows a multilingual document opened in a TMX editor.

In Figure 1, the <header> element contains a "srclang" attribute. Valid values for this attribute are "*all*" or a language code that's present in all translation units. When the "srclang" attribute is set to a specific language, the file is intended to be used only for translating in one direction: from the source language to another language. The value "*all*" is used when the file can be used to translate in any direction —from any language to any other language— something that not all CAT tools can do.
You can exchange translation memories using TMX documents at two levels:
<seg> elements do not
contain any inline tags.In theory, any tool that supports TMX at Level 2 should be able to use the tags generated by another Level 2 compliant tool, but in the real world differences in implementation mean that tags can't be reused.
All major CAT tools currently support the TMX standard, but some compatibility issues still exist:
<header/> instead of <header></header>.
Version 2.0 of TMX will attempt to correct some of the problems mentioned above. A draft of TMX 2.0 is available in TMX home page at LISA's web site.
TMX 2.0, in its current draft, includes a new set of inline tags designed to be compatible with XLIFF standard. It also has a new set of rules for selecting inline elements. Only one level of compliance is defined, thereafter all tools that implement support for TMX 2.0 should include inline markup in exported TMX files.
Thanks to a process called alignment, you can still reuse translations that are not part of a TM engine. An alignment tool needs two files, an original document and its translation, to generate a TMX file that can be imported into a TM system. A simple alignment method might look like this:
<source> elements from all translation units of the
newly-generated XLIFF files and create two lists, one for each file.<tuv> elements.
The process described above aligns two XLIFF files, not the original documents. Original
formatting information is converted to XLIFF inline tags, so that it can then be wrapped in
<ph> elements. The advantage of aligning documents this way is that the
resulting segments can be used with any XLIFF-compliant tool without complicated and
error-prone tag transformations.
The result of the alignment process depends on the quality of the translation. If the aligned documents have the same or very similar structure, the translation can be recovered for reuse without much effort. When translation is performed using a CAT tool, structure and formatting are usually preserved.
In the first article in this series, I mentioned that TermBase eXchange (TBX) is the appropriate XML format for preparing glossaries. Nevertheless, TMX can also be used for creating and maintaining multilingual glossaries.
TMX includes the elements <prop> and <note>, which can be used for adding terminological information to a document.
Listing 1 shows how to annotate a TMX file with terminological data using elements available in the TMX DTD.
<?xml version="1.0" encoding="UTF-8" ?>
<tmx version="1.4">
<header adminlang="en"
creationtool="Swordfish Translation Editor"
creationtoolversion="1.0"
datatype="tbx"
o-tmf="unknown"
segtype="block"
srclang="en"/>
<body>
<tu origin="tbx" tuid="1108600011738">
<tuv xml:lang="en">
<prop type="administrativeStatus">admittedTerm-admn-sts</prop>
<prop type="termType">entryTerm</prop>
<prop type="usageNote">Colloquial use term</prop>
<note>Informal salutation</note>
<seg>Hello</seg>
</tuv>
<tuv xml:lang="es">
<prop type="administrativeStatus">admittedTerm-admn-sts</prop>
<prop type="termType">entryTerm</prop>
<prop type="usageNote">Termino de uso coloquial</prop>
<note>Saludo informal</note>
<seg>Hola</seg>
</tuv>
</tu>
</body>
</tmx>
Listing 1. TMX file with terminological information
The team that wrote the TMX specifications noticed that the TMX standard is not enough for managing terminological data and created the TBX standard. This new standard is better suited for creating and maintaining dictionaries and glossaries, but TMX provides a good alternative for beginners.
It is important to note that as TMX and TBX are both XML-based, it is possible to use XSL transformations to convert data from one format to the other.
Glossaries in either TMX or TBX format can be used by CAT tools to provide partial translations in a Machine Translation-like style. I mentioned before that one of the best ways to ensure high quality matching requires that you divide the text to be translated into very small fractions. Translations are extracted from TM databases when a number of fragments above the required similarity percentage match database entries. In a similar fashion, it is possible to retrieve partial translations when a certain number of fragments exactly match all the fragments in a glossary entry.
Extracting partial translations from a glossary —usually a few words in a sentence— and presenting them to the translator in a clear way helps the translator to achieve coherency throughout the whole document.
This article has explained the importance of translation memories and how the localization industry uses them, highlighting the relevance of the TMX format for transferring translation data between different TM implementations.
I also presented a brief explanation of an alignment process used to recover legacy translations, illustrating how you can use other related standards like XLIFF to help solve a common problem.

Rodolfo M. Raya is involved in the development of localization standards including XLIFF, TMX, TBX, SRX, and GlossML.
He develops tools and libraries that implement these specifications, including the software and validation services available on this site.